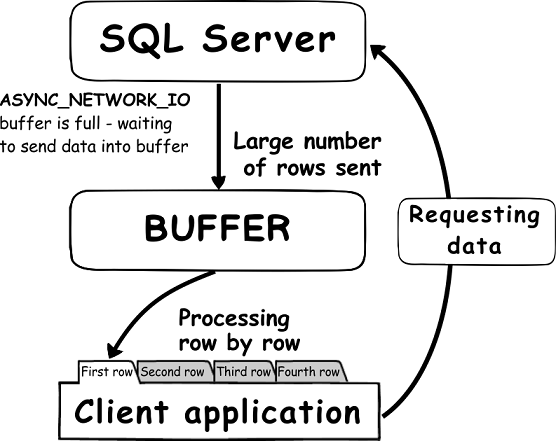
SQL Server Resource Governor was introduced in SQL Server 2008. This feature is used to control the consumption of the available resources, by limiting the amount of the CPU, Memory and IOPS used by the incoming sessions, preventing performance issues that are caused by resources high consumption.
The Resource Governor simply differentiates the incoming workload and allocates the needed CPU, Memory and IOPS resources based on the predefined limits for each workload. In this way, the SQL Server resources will be divided among the current workloads reducing the possibility of consuming all resources by single workload type, while competing for the available resources. A minimum resources limit can be also specified in the Resource Governor, which allows you to set the proper resource level for each workload type.
The Resource Governor feature is very useful when you have many databases hosted in your SQL Server and many applications connecting to these databases. These connections are competing for the available SQL Server resources, affecting each other’s performance. Using the Resource Governor feature will overcome this kind of performance issue.
There are three main components that form the Resource Governor; Resource Pools, Workload Groups and the Classifier. Small chunks of the CPU, Memory and IOPS resources are collectively called the Resource Pool. A set of defined connections is known as Workload Group. The component that is responsible for classifying incoming connections to workload groups, depending predefined criteria, is called the Classifier. We will review each these components, in detail, in this article.
Resource Pools represent virtual instances of all of the available SQL Server CPU, Memory and IOPS resources. There are two built-in resource pools created when you install the SQL Server; the Internal Pool, which is used for the SQL Server background tasks, and the Default Pool, which is used to serve all user connections that are not directed to any user-defined resource pool. The internal pool can’t be modified, as it is used for serving SQL Server background processes. If the internal pool needs all the SQL Server available resources for a specific internal task, it will be given priority over all other user-defined pools. SQL Server supports up to 18 user-defined resource pools.
While creating resource pools, you need to specify the CPU, Memory and IOPS minimum and maximum limitations for each pool. The MIN_CPU_PERCENT parameter specifies the minimum CPU used by all requests in the created pool, which takes effect when CPU contentions occur, as the value will be available for other pools if there is no activity in the pool. This value can be between 0 and 100, with the sum of the MIN_CPU_PERCENT value for all pools not more than 100%. The MAX_CPU_PERCENT parameter specifies the maximum CPU used by all requests in the created pool. Same as the MIN_CPU_PERCENT parameter, the MAX_CPU_PERCENT takes effect when CPU contentions occurred, as the value will be available for other pools if there is no activity in the pool. The MAX_CPU_PERCENT value can’t be less than the MIN_CPU_PERCENT value. For the MIN_MEMORY_PERCENT setting, it will be reserved for the pool whether it is used or not, and will not be released for the other pools if there is no activity on that pool, which will affect the overall performance if you set a high value for less frequently used pool. Again the MAX_MEMORY_PERCENT parameter should be more than the MIN_MEMORY_PERCENT value.
Workload Groups are containers for user and system sessions with a common classification type that will be mapped to one resource pool. There are two built-in workload groups created when the SQL Server is installed; internal SQL Server activities are grouped into the Internal Workload Group, which is mapped to the Internal Pool, and user activities that are not directed to any user-defined workload group, which will be grouped into the Default Workload Group that is mapped to the Default Pool.
There are many parameters that you can tune during the workload group creation process, such as specifying the session’s importance within the group, otherwise referred to as IMPORTANCE. Importance is compared and affected to the same resource pool. Importance can be LOW, MEDIUM and HIGH, where MEDIUM is the default value.
-
The REQUEST_MAX_CPU_TIME_SEC parameter specifies the maximum CPU time that can be used by the session. An alert will be raised if the session exceeds that value without interrupting the session. The value 0 indicates no limit for session’s CPU time.
-
The MAX_DOP value specifies that maximum degree of parallelism used by the parallel sessions. This value will override the default server MAXDOP value for the parallel sessions. The MAX_DOP value can be between 0 and 64.
-
The REQUEST_MEMORY_GRANT_TIMEOUT_SEC parameter specifies the maximum time that the query will wait to be granted memory once it is available.
-
The REQUEST_MAX_MEMORY_GRANT_PERCENT specifies the maximum memory that the session can use from the resource pool. The default value for the
REQUEST_MAX_MEMORY_GRANT_PERCENT is 25.
-
The GROUP_MAX_REQUEST specifies the maximum number of concurrent sessions that can be executed in the workload group.
The Classifier is a function that is used to categorize incoming sessions into the appropriate workload group. Many system functions can be used to classify the incoming sessions such as: HOST_NAME (), APP_NAME (), SUSER_NAME (), SUSER_SNAME (), IS_SRVROLEMEMBER (), and IS_MEMBER (). Only one classifier function can be used to direct the sessions to the related workload group. It is better to keep the classifier function as simple as possible, as it will be used to evaluate each incoming session, and with complex function it will slow down the incoming queries and affect overall performance.
We described each component individually, now we need to combine it all together to know how the Resource Governor works. Simply, once the session connected to the SQL Server, it will be classified using the classifier function. The session will be routed to the appropriate workload group. This workload group will use the resources available in the associated resource pool. The resource pool will provide the connected session with limited resources.
The process of configuring the SQL Server Resource Governor is simple; first you need to create the resource pools, then create a workload group and map it to a resource pool, after that the classification function should be created to classify the incoming requests and finally the resource governor will be enabled with the created classification function.
Let’s start with creating two resource pools, the ServicePool that will be used for the service accounts and the UserPool that will be used for the user accounts as below:
CREATE RESOURCE POOL [ServicePool] WITH(
min_cpu_percent=50,
max_cpu_percent=100,
min_memory_percent=50,
max_memory_percent=100,
AFFINITY SCHEDULER = AUTO
)
GO
CREATE RESOURCE POOL [UserPool] WITH(
min_cpu_percent=0,
max_cpu_percent=30,
min_memory_percent=0,
max_memory_percent=30,
AFFINITY SCHEDULER = AUTO
)
GO
As you can see, the ServicePool assigned resources more than the UserPool, in order to give priority for the requests coming from the application side over the users’ ad-hoc queries.
Now the two resource pools are ready, we will start creating two workload groups; ServiceGroup that will be mapped to the ServicePool resource pool and the UserGroup that will be mapped to UserPool resource pool, keeping all other parameters with its default values as follows:
CREATE WORKLOAD GROUP [ServiceGroup]
USING [ServicePool]
GO
CREATE WORKLOAD GROUP [UserGroup]
USING [UserPool]
GO
To make sure that the changes will take effect, the RECONFIGURE statement should be run as below:
ALTER RESOURCE GOVERNOR RECONFIGURE;
GO
Now that the resource pools and workload groups have been created and configured successfully, ou can now create the resource pools and workload groups simply using SQL Server Management Studio. Expand the Management node from the Object Explorer, then right-click on the Resource Governor and choose New Resource Pools as follows:
![]()
The Resource Governor Properties window will be displayed, where you will find two default resource pools in the top grid, the Default and Internal resource pools. You can create the two user-defined resource pools created previously by specifying the pool name and the CPU and Memory min and max limitations. Then by clicking on each created pool, you can create workload groups that will be mapped to the selected resource pool. And finally enable the resource governor by checking the Enable resource Governor checkbox as below:
![]()
You will not be able to choose the classifier function that will be used in the previous window as it is not created yet. Refresh the Resource Governor node to check that the resource pools and the workload groups created successfully:
![]()
You can also use the sys.resource_governor_resource_pools and sys.resource_governor_workload_groups DMVs to list the created resource pools and workload groups with all settings as in the following simple SELECT statements with the results:
SELECT * FROM sys.resource_governor_resource_pools
![]()
SELECT * FROM sys.resource_governor_workload_groups
![]()
Now, we will create the classification function that will be used to classify and route the incoming requests to the appropriate workload group. In this example, we will classify the incoming requests depending on the user name as service or normal users, using the SUSER_SNAME() system function as follows:
USE master;
GO
CREATE FUNCTION Class_funct() RETURNS SYSNAME WITH SCHEMABINDING
AS
BEGIN
DECLARE @workload_group sysname;
IF ( SUSER_SNAME() = 'ramzy')
SET @workload_group = 'UserGroup';
IF ( SUSER_SNAME() = 'SQLShackDemoUser')
SET @workload_group = 'ServiceGroup';
RETURN @workload_group;
END;
To enable the Resource Governor using the created classification function, use the ALTER RESOURCE GOVERNOR query below:
USE master
GO
ALTER RESOURCE GOVERNOR WITH (CLASSIFIER_FUNCTION = dbo.Class_funct);
GO
ALTER RESOURCE GOVERNOR RECONFIGURE;
The sys.resource_governor_configuration DMV can be used to make sure that the Resource Governor is enabled as follows:
SELECT * FROM sys.resource_governor_configuration
![]()
Congratulations, the Resource Governor is configured successfully and will start catching each connected session, routing the connections from SQLSHACKDEMO user to the ServiceGroup, the connections from Ramzy user to UserGroup, the SQL Server background processes to the Internal workload group and any other connections, to the Default workload group.
The below query can be used monitor the incoming sessions with the workload group for each session except the internal sessions (remove the WHERE clause to monitor all sessions):
USE master
GO
SELECT ConSess.session_id, ConSess.login_name, WorLoGroName.name
FROM sys.dm_exec_sessions AS ConSess
JOIN sys.dm_resource_governor_workload_groups AS WorLoGroName
ON ConSess.group_id = WorLoGroName.group_id
WHERE session_id > 60;
The results will be like:
![]()
We can also use the performance monitor counters to monitor the Resource Governor. The CPU usage % counter from the SQLServer: Workload Group Stats counters set is used to monitor the CPU usage by all requests in the selected workload group. And the Used memory (KB) performance counter from the SQLServer: Resource Pool Stats counters set retrieves the amount of memory used by each resource pool.
Assume that we will run the below DBCC CHECKDB queries concurrently by the SQLSHACKDEMO and Ramzy users in order to monitor both the CPU and Memory usage per each workload group they belong to:
USE master
GO
DBCC checkdb (AdventureWorks2012 )
GO
DBCC checkdb (AdventureWorksDW2012 )
GO
DBCC checkdb (ApexSQLCrd )
GO
DBCC checkdb (ApexSQLMonitor )
GO
DBCC checkdb (SQLShackDemo )
GO
Open the Windows Performance Monitor window from the Administrative tools or by writing Perfomon on the Run window, then click on Plus (+) icon to add the needed performance counters. First we will choose the CPU Usage% counter from the SQLServer: Workload Group Stats counters set for the two user-defined resource pools created previously as follows:
![]()
As you can see in the middle part of the result below, the ServicePool represented by the red line is assigned more CPU than the UserPool represented by the green line, as the CPU for the UserPool is limited to 30 percent only. Once the query that is running on the ServicePool finished, the UserPool limitation is overridden and assigned all CPU resources requested by that session to complete the query as appeared in the last part of the below graph. Once both queries are finished, all CPU resources released back to the other pools showing zero CPU percent for both pools below:
![]()
To discuss the memory usage on each pool, choose the Used memory (KB) counter from the SQLServer: Resource Pool Stats counters set for the two user-defined resource pools created previously as follows:
![]()
It is clear from the middle part of the graph below, that the ServicePool represented by the blue line assigned more memory than the UserPool represented by the purple line during the concurrent run of both sessions. Once the session running in the ServicePool completed, the session running on the UserPool will not override the defined limit and will complete running in the same memory limit. The other thing that we should mention is that, once the sessions are finished, the memory will not be completely released, reserving the minimum memory required for the sessions, although there is no incoming requests on that pools as follows:
![]()
The SQL Server 2014 Resource Governor allows you to limit another server resource in addition to the CPU and Memory to manage the server performance, which is the IOPS (Input Output Operations per Second) per volume. If one of your applications performs an intensive IO load, it will affect the overall SQL Server IO performance, slowing down the other applications connecting to that SQL Server. With this new addition in SQL Server 2014, you can control the IO consumption by specifying the MIN_IOPS_PER_VOLUME and MAX_IOPS_PER_VOLUME parameters while creating the resource pool.
Let’s modify the ServicePool and the UserPool that we created in our demo to set the MAX_IOPS_PER_VOLUME value using ALTER RESOURCE POOL query below:
ALTER RESOURCE POOL ServicePool WITH (Max_IOPS_PER_VOLUME=1500);
ALTER RESOURCE GOVERNOR RECONFIGURE;
GO
ALTER RESOURCE POOL UserPool WITH (Max_IOPS_PER_VOLUME=500);
ALTER RESOURCE GOVERNOR RECONFIGURE;
GO
The sys.dm_resource_governor_resource_pools DMV can be used again to check our resource pools settings including the CPU, Memory and IOPS limits as follows:
SELECT pool_id , name, min_cpu_percent ,max_cpu_percent ,min_memory_percent ,max_memory_percent ,min_iops_per_volume ,max_iops_per_volume from sys.dm_resource_governor_resource_pools
The result will be like:
![]()
The Disk Read IO/Sec performance counter from the SQLServer: Resource Pool Stats counters set can be used to monitor the IOPS load for the two user-defined resource pools created previously as follows:
![]()
You can see from the below graph how the Resource Governor limits the IOPS used by the UserPool represented by the blue line not to exceed the 500 IOPS, where it allow the ServicePool to exceed that value but limited to 1500 IOPS as per our configuration. Once the sessions finished, both will release the IOPS to the other pools on that SQL Server:
![]()
If you arrange to modify the classification function or disable the Resource Governor, you should disconnect the Resource Governor from the classification function by assigning it to NULL as follows:
ALTER RESOURCE GOVERNOR WITH (CLASSIFIER_FUNCTION = null);
GO
ALTER RESOURCE GOVERNOR RECONFIGURE;
Null means that all incoming requests will be routed to the Default pool. To complete disabling the Resource Governor, run the simple ALTER RESOURCE GOVERNOR query below:
ALTER RESOURCE GOVERNOR DISABLE;
GO
ALTER RESOURCE GOVERNOR RECONFIGURE;
You need to make sure that all sessions connected to that SQL server are stopped, in order to completely disable the Resource Governor, and the best way to guarantee that is restarting the SQL Server Service using the SQL Server Configuration Manager.
Conclusion:
The SQL Server Resource Governor enables you to limit the CPU, Memory and recently the IOPS resources requested by the incoming sessions. In this way, you will prevent high resource consuming queries from affecting the performance of other queries and slowing down the applications connecting to the SQL Server.
On the down side, the Resource Governor has few limitations, such as it can be used to limit the resources only for the SQL Server Database Engine, and can’t be configured to limit the other SQL Server components such as Reporting Services, Integration services or Analysis Services. Also, the Resource Governor has no control over system activities that can consume all server resources, and only limit user activities.
Useful Links:
The post The SQL Server 2014 Resource Governor appeared first on SQL Shack - articles about database auditing, server performance, data recovery, and more.